[전처리] 파이썬을 활용한 자산별 상관관계 구하기 #1
by 소라고동_0. 들어가며
해당 포스팅은 아래의 포스팅에 들어있는 자산별 상관관계를 파이썬으로 시각화하는 과정 중 전처리를 진행한 내용을 담고있습니다.
복잡하거나 어려운 전처리 과정이 전혀 없으니 가볍에 살펴보셔도 될 것 같습니다.
그래도 이 내용이 궁금하지 않으시면 아래 링크만 확인하셔도 됩니다.
2021.08.16 - [분류 전체보기] - [종합] 파이썬을 활용한 자산별 상관관계 구하기
1. 자산별 가격 데이터 수집하기
자산별 상관관계를 파악하기 위해서는 자산들의 시계열 데이터가 필요합니다.
구글링을 통해 열심히 찾아본 결과 아래의 사이트에서 원하는 데이터값을 내려받을 수 있었습니다.
주식시장 시세와 금융뉴스 - Investing.com
Investing.com은 무료 실시간 시세, 포트폴리오, 챠트, 최신 금융 뉴스, 주식시장 데이터 및 기타를 제공.
kr.investing.com
제가 사용한 자산 이외에도 다양한 자산들의 가격 데이터가 있으니 필요하시다면 한번 확인해보셔도 좋겠습니다.
우선 코스피 시장이 시작된 1980년 데이터부터 사용하기로 했고, 월 단위 데이터를 불러왔습니다.
일 단위 데이터를 사용하지 않은 이유는 아래와 같습니다.
약 40년의 기간동안의 시계열 데이터라면 월 단위 데이터만으로도 자산별 상관관계를 충분히 파악할 수 있다.
장기적인 투자 관점에서 하루하루 자산별 가격을 지나치게 신경쓸 필요가 없다.
이러한 이유로 40년간의 월 단위 데이터를 수집했습니다.
불러온 데이터의 모습은 이렇습니다.
| 영문 컬럼명 | 설명 |
| date | 기준년월 |
| S&P500 | S&P500 지수 |
| NASDAQ | 나스닥 지수 |
| US_Bond | 미국 국채 10년물 |
| KOSPI | 코스피 지수 |
| ex_rate | 원달러 환율 |
| Gold | 국제 금시세 |

컬럼명이나 날짜 형식으로의 변환 등 엑셀을 이용해서 간단하게 처리할 수 있는 작업들은 엑셀로 진행했습니다.
이제 이 데이터를 주피터 노트북으로 들고와 파이썬을 활용해 조금 더 세세하게 다뤄보도록 하겠습니다.
2. 데이터 전처리하기
2.1. 라이브러리 불러오기 및 기본 환경설정
우선 이번 작업을 진행할 때 사용할 패키지를 불러옵니다.
import pandas as pd import numpy as np import matplotlib.pyplot as plt from datetime import datetime %matplotlib inline import seaborn as sns
pandas, numpy, datetime 는 데이터 전처리를 위해 사용할 라이브러리이고, matplotlib 와 seaborn 은 전처리된 패키지를 시각화 하기위해 불러왔습니다.
그리고 matplotlib 를 활용해 시각화를 진행할 때, 한글 깨짐 현상을 해결하기 위해 폰트를 불러옵니다.
import matplotlib as mpl import matplotlib.font_manager [f.name for f in matplotlib.font_manager.fontManager.ttflist if 'Nanum' in f.name] # 유니코드 깨짐현상 해결 mpl.rcParams['axes.unicode_minus'] = False # 나눔고딕 폰트 적용 mpl.rcParams["font.family"] = 'NanumGothic' # 그래프 전역으로 설정하기 # plt.rcParams.keys() parameters = { 'axes.labelsize' : 15, 'xtick.labelsize' : 13, 'ytick.labelsize' : 13 } plt.rcParams.update(parameters)
2.2. 데이터 정제 및 살펴보기
이제 사용할 데이터를 불러옵니다.
asset = pd.read_csv("Asset_data.csv") asset
asset 이라는 이름으로 데이터프레임을 불러왔습니다.
몇몇 데이터에 NaN 값이 있는데 하나의 자산이라도 NaN 값이 존재한다면 해당 기준년월을 제거한 뒤 진행할 예정입니다.우선 컬럼별 타입(type), 통계값을 확인해봅시다
asset.dtypesdate 를 제외한 다른 컬럼은 float64 타입(실수를 64비트로 나타냄) 입니다.
이렇게 모든 값이 예쁘게 float64 로 되어있는 이유는 엑셀에서 타입을 바꾼 뒤 들고왔기 때문입니다.
파이썬에서도 타입을 변경할 수 있지만, 이왕 엑셀을 통해 데이터를 불러온 것이라면 미리 할 수 있는 작업은 간단히 하고 불러오는 것도 나쁘지 않습니다.
date 컬럼은 날짜 타입으로 변경한 뒤 인덱스로 만들어주려 합니다.
asset.describe()각 자산들의 기초통계량을 확인해봤습니다. 가격데이터는 곧 수익률로 변환시킬 값들이기 때문에 결측치의 유무를 중점으로 확인했습니다.
S&P500, Gold 를 제외하고는 모두 결측치가 존재하네요.
그 외의 값들은 자산별 스케일 차이가 많이 나기 때문에 비교가 어려워 그래프로 자산의 추세를 알아봤습니다.
# 그래프로 확인해보자 (자산 가격) plt.figure(figsize=(20, 10)) plt.plot(new_asset.index, new_asset['S&P500'], color = 'r') plt.plot(new_asset.index, new_asset.US_Bond, color = 'g') plt.plot(new_asset.index, new_asset.NASDAQ, color = 'b') plt.plot(new_asset.index, new_asset.KOSPI, color = 'y') plt.plot(new_asset.index, new_asset.ex_rate, color = 'm') plt.plot(new_asset.index, new_asset.Gold, color = 'k') plt.legend(['S&P500', 'us_bond', 'NASDAQ','Kospi', 'ex_rate', 'Gold'], fontsize=12, loc='best')
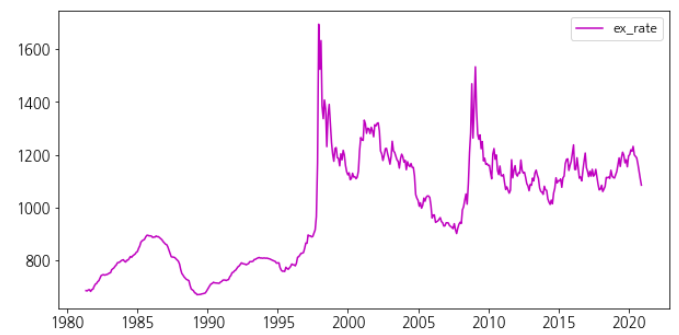
(전체 추세그래프에서 US_Bond 와 ex_rate 가 잘 확인되지 않아 따로 뽑아봤습니다.)
파란색 선에 해당하는 NASDAQ 의 경우 가장 큰 폭의 상승을 보였고 , S&P500, KOSPI, GOLD, US_BOND 도 크진 않지만 꾸준한 상승곡선을 그리고 있음을 확인할 수 있습니다.
환율의 경우 일정한 박스권에서 등락을 반복하는 것을 확인할 수 있습니다.
2.3. 날짜 타입으로 변경하고 인덱스로 만들기
현재는 date 열의 타입이 object 로 되어있는데 이를 날짜 타입으로 바꾼 뒤 인덱스로 만들어주도록 하겠습니다.
날짜를 인덱스로 넣어주면 인덱싱을 할 때 매우 편리해진다는 장점이 있습니다!
문자열을 datetime 으로 변환하기 위해서 datetime.strptime() 메서드를 사용합니다.
strptime() 메서드는 문자열을 원하는 형태의 datetime으로 변환시켜줍니다.
date_tmp = '2020-01' datetime.strptime(date_tmp, '%Y-%m')
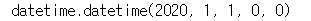
결과를 살펴보면 '2020-01' 이라는 문자열을 '%Y-%m' 포맷으로 바꾸어줬는데 이는 "네 자릿수 연도 - 숫자 월" 로 바꿔달라는 의미입니다.
그런데 바꿔보니 '일' 단위릐 숫자도 생겨났습니다. 분석을 진행하는데 문제가 없으니 그냥 진행했습니다.
문자열이 날짜 포멧으로 바뀐다는 것을 확인했으니 date 칼럼의 모든 행에 대해서 타입 변환을 진행해줬습니다.
date = asset['date'] new_date = [ datetime.strptime(d, '%Y-%m') for d in date ] new_date
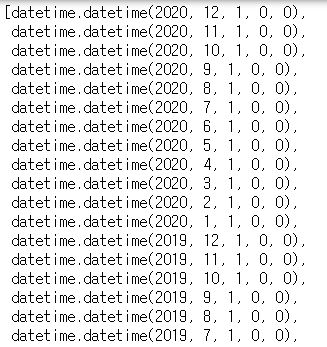
리스트와 반복문을 이용해서 모든 행에 대해 처리를 해주었고, 이제 이 변환값들을 다시 데이터프레임에 넣어주었습니다.
asset['date'] = new_date asset.dtypes

date 컬럼의 자료형이 datetime64 로 바뀌었음을 확인할 수 있습니다.
그리고 date 컬럼을 Index 로 만들어주고 해당 컬럼을 삭제해주었습니다.
new_asset = asset.set_index(asset['date']) new_asset = new_asset.drop(['date'], axis = 1) new_asset = new_asset.sort_values(by = ['date']) new_asset
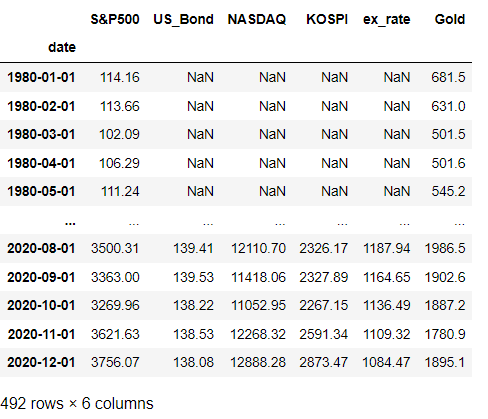
이렇게 예쁘게 인덱스로 들어가있는 모습을 확인할 수 있습니다.
날짜를 인덱스로 만들어주면 슬라이싱이나 인덱싱을 할 때 유용합니다.
new_asset['2019-05':'2020-02']
이렇게 간단하고 직관적으로 슬라이싱을 할 수 있습니다!
2.4. 결측치 제거하기
정제한 new_asset 데이터프레임을 보면 NaN 값이 존재합니다.
이를 보다 상세히 살펴보기 위해 isnull() 메서드를 이용해서 컬럼별로 NaN 값의 개수를 확인해봤습니다.
new_asset.isnull().sum()
S&P500, Gold 를 제외하면 1년 ~ 6년 가까이의 시계열 값이 빠져있음을 확인할 수 있습니다.
NaN 값을 처리하는 방식은 여러가지가 있는데 여기서는 NaN 이 있는 행을 제거하는 방식으로 처리하였습니다.
결측치를 제거한 이유를 살펴보면
해당 NaN 값은 수집되지 않은 과거의 데이터에만 나타남.
→ 시계열 분석에 문제가 되지 않음.
NaN 값에 대체값을 넣는 경우에는 자산별 상관관계에 영향을 미칠 수 있을것이라고 생각함.
해당 값들을 삭제하여도 충분히 긴 시간의 데이터가 확보된 상태.
이런 이유로 결측치를 제거하였습니다.
new_asset = new_asset.dropna() new_asset
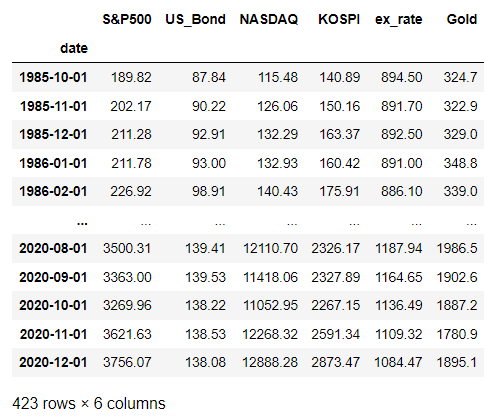
거의 다 왔습니다!
2.5. 데이터 값을 수익률로 변환하기
마지막으로 데이터의 값을 수익률로 변환시켜줍니다.
값이 아닌 수익률을 사용하는 이유는 가격이 가지고있는 추세를 없애기 위함입니다.
파이썬에서는 df.pct_change() 메서드를 활용하면 컬럼별로 수익률을 구해줍니다.
asset_rate = new_asset.pct_change() asset_rate = asset_rate.dropna() asset_rate = asset_rate * 100 asset_rate
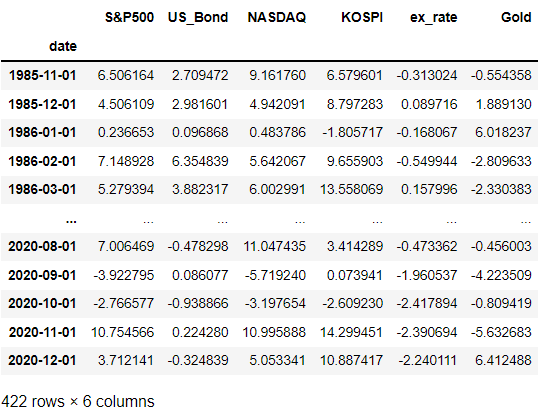
이렇게 우리가 활용할 데이터프레임이 완성되었습니다.
1985년 10월의 값이 사라진 이유는 수익률을 구하는 공식 때문입니다.
(기준시점 가격 - 비교시점 가격)/ 비교시점 가격
1985년 10월의 경우 비교시점인 1985년 9월 값이 없었기 때문에 NaN 값이 출력됩니다.
그래서 다시한번 NaN 값을 제거해주었고, 이로인해 1985년 10월의 값이 제거되었습니다.
3. 시각화하기
이제 이 테이블로 시각화를 진행할텐데 이 부분은 다음 포스팅에서 진행하도록 하겠습니다!
< 다음 포스팅 보러가기! >
2021.08.17 - [분류 전체보기] - [시각화] 파이썬을 활용한 자산별 상관관계 구하기 #2

블로그의 정보
고동의 데이터 분석
소라고동_![[시각화] 파이썬을 활용한 자산별 상관관계 구하기 #2 글의 미리보기 사진](https://img1.daumcdn.net/thumb/R100x0/?scode=mtistory2&fname=https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcQiMvB%2Fbtrci9MSLm5%2FwkHiA0sKj86mvK02CXu9k0%2Fimg.png)
![[종합] 파이썬을 활용한 자산별 상관관계 구하기 (feat. 자산 포트폴리오) 글의 미리보기 사진](https://img1.daumcdn.net/thumb/R100x0/?scode=mtistory2&fname=https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FUfmfs%2FbtrcgPs3aGb%2FCI4k5PIUodlgmD2k8x3sT1%2Fimg.png)