[SQL] 윈도우 함수(Window Function)의 소중함을 느껴보자
by 소라고동_0. 들어가며
요즘에는 대부분의 DBMS에서는 윈도우 함수(Window Function)를 제공하고 있습니다.
업무를 하다보면 여러 서브쿼리를 이용하여 만들어야 할 결과물을 윈도우 함수를 활용해 아주 간단하게 만들 수 있는 경우가 많습니다.
이렇게 간편한 윈도우 함수가 없었을 시절에는 어떻게 결과값들을 만들었을까요?
이번 시간에는 윈도우 함수가 없다면 어떻게 쿼리를 작성했을지를 생각해보며 윈도우 함수의 소중함을 느껴보는 시간을 가져보도록 하겠습니다.
0.1. 윈도우 함수(Window Function)란?
우선 윈도우 함수가 무엇인지 아주 간단하게 설명하고 넘어가도록 하겠습니다.
윈도우 함수의 정의를 찾아보면 다음과 같습니다.
윈도우 함수(Window Function)
= 행과 행간의 관계를 쉽게 정의 하기 위해 만든 함수를 이름
기존의 SQL 언어는 컬럼과 컬럼간의 연산, 비교, 집계에 특화되어있는 언어였습니다.
반면 행과 행간의 관계를 정의하거나 비교, 연산하는 것은 하나의 SQL 문으로 처리하기 어려웠죠.
이러한 부분을 쉽게 처리하기 위해 생겨난 것이 윈도우 함수입니다.
윈도우 함수의 생김새를 살펴보면 아래와 같습니다.
* 함수(컬럼) OVER (Partition by 컬럼 Order by 컬럼)
함수 : Min, Max, Sum, Count, Rank 등과 같은 기존의 함수 or 윈도우 함수용으로 추가된 함수 (Row_number 등)
OVER : over 은 윈도우 함수에서 꼭 들어가야 하며 Over 내부에 Partition By 절과 Order by 절이 들어갑니다.
partition by : 전체 집합을 어떤 기준(컬럼)에 따라 나눌지를 결정하는 부분.
order by : 어떤 항목(컬럼)을 기준으로 순위를 정할 지 결정하는 부분
적용할 함수와 Over 절은 윈도우 함수에서 필수적으로 사용되며, 어떤 결과를 만들어낼지에 따라 partition by 와 order by 절을 사용하게 됩니다.
0.2. group by 와 차이점
윈도우 함수의 생김새를 살펴보면 어떤 기준에 따라 Partition by, 즉 나누어 집계한다는 것을 알 수 있습니다.
그렇다면 group by 와는 어떤 차이가 있을까요?
| group by | 윈도우 함수 | |
| 기능 | 자르기 + 집약 | 자르기 |
| 특징 | 1. group by 구에 지정된 컬럼으로 데이터를 자르고 2. 집계 함수를 이용해 집약시킨다. |
1. partition by 구에 지정된 컬럼으로 데이터를 자른다. |
| 차이점 | 행의 수가 줄어든다 | 행의 수가 그대로 유지된다. |
위 표에 대해서 간략히 설명을 해보겠습니다.
group by 와 윈도우 함수의 가장 큰 차이는 '집약'의 과정이 존재하는가? 입니다.
예시를 활용해 이해를 해봅시다.
< group by 를 사용한 경우>
select address, count(*)
from address
group by 1;
< 윈도우 함수를 이용한 경우 >
select address , count(*) over(partition by address)
from address;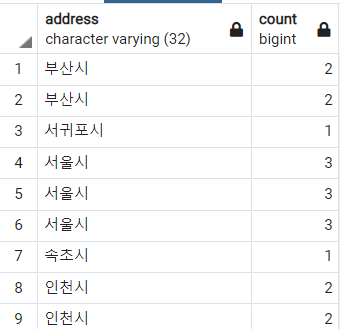
위 두 경우를 살펴보면 차이점을 알 수 있습니다.
group by 는 집약 기능으로 인해 행 수가 줄어든 반면, 윈도우 함수는 행 수가 그대로 남아있습니다.
윈도우 함수에는 집약의 기능이 없기 때문입니다.
이러한 특징을 이용해서 우리는 행과 행간의 관계를 편하게 다룰 수 있게 됩니다!
1. 윈도우 함수의 소중함 알아보기
그렇다면 이제 윈도우 함수를 활용했을때와 그렇지 않을때를 비교하며 소중함을 느껴보도록 하겠습니다.
1.1. 레코드에 순번 붙이기
각 행에 순번을 붙이는 경우 윈도우 함수에서는 아주 간단하게 row_number 함수를 사용하면 됩니다.
우선 예제로 사용할 데이터의 생김새는 이렇습니다.
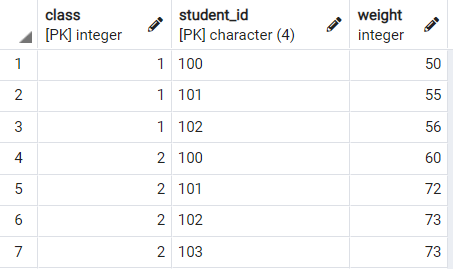
목적
: 각 행에 대한 순번 만들기
< 윈도우 함수 사용 시 >
select class, student_id , row_number() over(order by class, student_id)
from weights;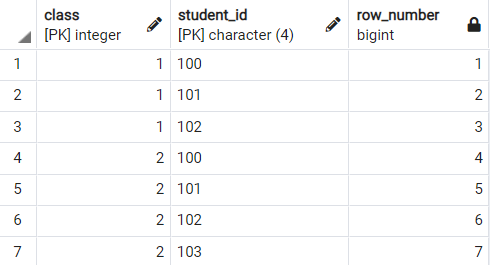
이렇게 간단하게 행에 대한 순번을 만들 수 있습니다.
그렇다면 row_number 함수를 지원하지 않는 DBMS를 사용하고 있거나 지원하지 않았을 때에는 어떻게 만들었을까요?
< 윈도우 함수를 사용하지 않을 때 >
select class, student_id
, (select count(*)
from weights a
where (a.class, a.student_id) <= (b.class, b.student_id)) as rownum
from weights b;위와 같이 select절에 서브쿼리를 활용하면 윈도우 함수를 사용했을 때와 같은 결과를 얻을 수 있습니다.
이 방법에 들어있는 원리는 다음과 같습니다.
1. 서브쿼리를 활용하여 재귀 집합을 만들어 준다.
= weights 테이블과 weights 테이블을 비교하도록 만들고, 조건을 부여하여 조건에 부합하는 행만 count 해줍니다
2. 다중 필드 비교를 사용한다.
= 여러 컬럼을 하나의 값으로 연결해 한꺼번에 비교를 해줍니다.
= 위의 예시로 설명을 해보자면,
'첫 행의 (class, student_id)인 (1,100)가 다른 행의 (class, student_id) 의 값보다 작거나 같은게 몇개가 있지?' 를 고려해 보는
방식입니다.
(1,100)의 경우 자신밖에 없으니 1 이 출력, (1,101) 의 경우 자기 자신과 (1,100)이 존재하니 2 ... 이런 식으로 카운팅이 됩니다.
해당 조건들에 만족하는 행의 개수를 세어줌으로써 각 행에 순번을 달아줄 수 있습니다.
이렇게 윈도우 함수와 select 서브 쿼리를 이용한 결과를 비교해보면, 윈도우 함수를 활용한 쿼리가 훨씬 보기 간편하고 작성이 편리하다는 것을 확인할 수 있습니다.
그리고 윈도우 함수의 경우 weight 테이블을 1회 스캔하지만, 서브쿼리를 활용할 경우 weight 테이블을 2회 스캔하게 됩니다.
이런 이유로 테이블 스캔의 관점에서 윈도우 함수가 조금 더 좋은 방식이라고 할 수 있다는 결론을 내릴 수 있습니다.
(뒤에서 이야기 할 내용이지만 윈도우 함수가 성능적으로 좋은 방식은 아니라고 합니다.)
1.2. 누적합 구하기
누적합을 만들고 싶을 땐 간단하게 윈도우 함수 구문에 sum 함수를 사용해주면 됩니다.
목적
: class별 student_id 의 몸무게의 누적합 구하기
(의미 없는 누적합이지만.. 다같이 엘리베이터를 탈 수 있는지 확인해보기 위함이라고 생각해봅시다)
< 윈도우 함수를 사용할 때 >
select class, student_id, weight
, sum(weight) over(partition by class order by student_id) as cum_weight
from weights;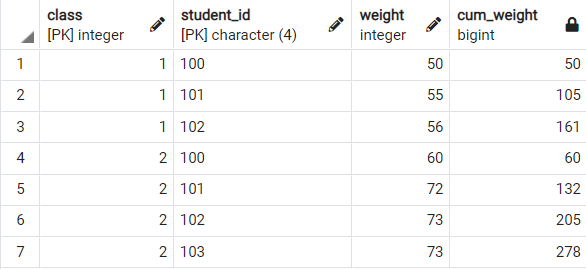
sum 을 윈도우 함수에서 활용할 때, order by절을 사용하면 순차적인 누적합을 구할 수 있습니다.
만약 order by절을 사용하지 않는다면, partition by 로 구분한 파티션에 존재하는 값들의 합이 도출됩니다.
(이 부분은 바로 다음 예시인 그룹 내 비율 구하기에서 활용해보겠습니다.)
< 윈도우 함수를 사용하지 않을 때 >
윈도우 함수를 사용하지 않는 경우의 프로세스를 하나씩 따라가보도록 하겠습니다.
select *
from weights a
join weights b
on (a.class = b.class -- 이게 하나의 파티션이 됨.
and a.student_id >= b.student_id)위 쿼리를 따라가보겠습니다.
1. weight 테이블과 weight 테이블을 Join 시켜 줍니다.
2. Join의 on 절에 a.class = b.class 를 넣어줌으로써 윈도우 함수의 Partition by 의 기능을 구현해줍니다.
3. 레코드의 순번을 구하는 것 처럼 a.student_id 와 b.student_id 를 비교해 줍니다.
→ 누적합도 누적시키는 순서가 필요하기 때문이 이렇게 순서를 만드는 방식을 차용해줍니다.
이렇게 만들어진 결과는 아래와 같습니다.
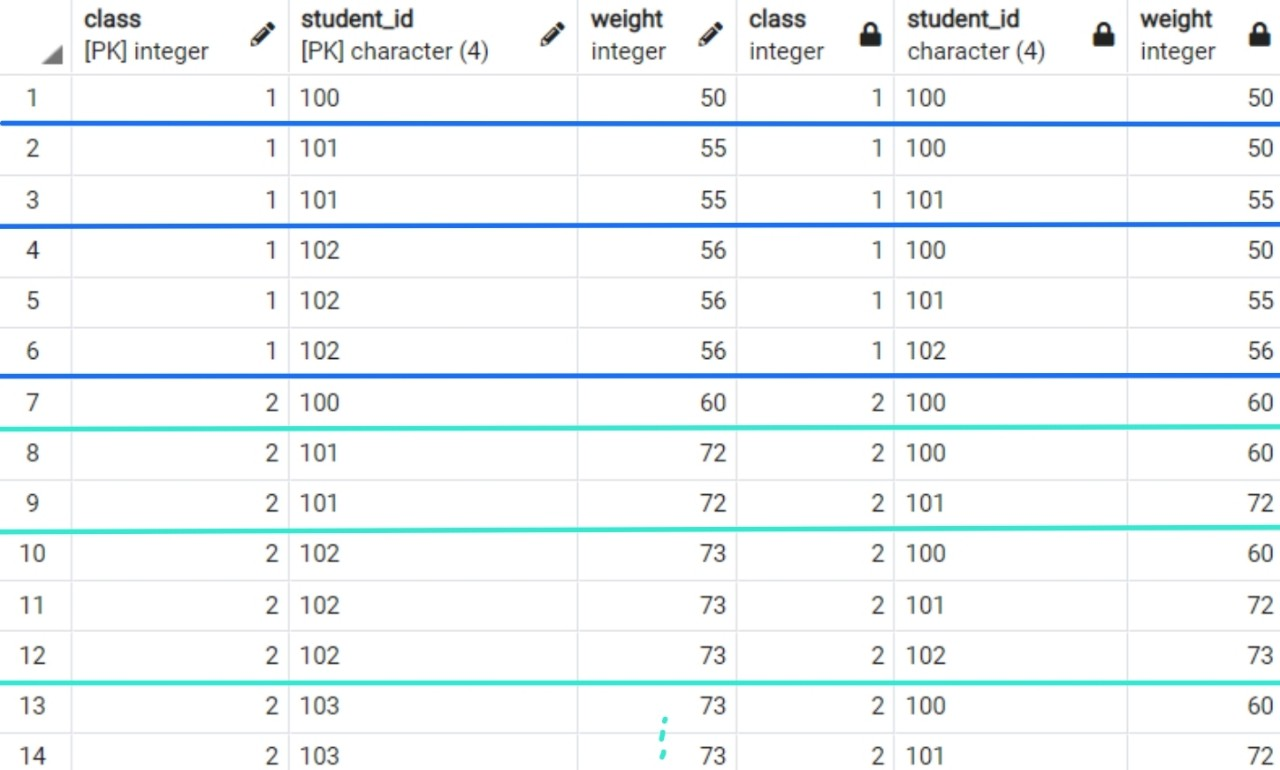
선을 그어 놓은 부분을 기준으로 살펴보면 이해가 쉽습니다.
class 별로 a.student_id >= b.student_id 인 조건에 맞는 값들을 join 시켜주었습니다.
이제 이 상태에서 b.weight 를 sum 해주면 누적합을 구할 수 있습니다.
select a.class, a.student_id, a.weight
, sum(b.weight) as cum_weight
from weights a
join weights b
on (a.class = b.class and a.student_id >= b.student_id) -- 이게 하나의 파티션이 됨.
group by 1,2,3
order by 1,2,3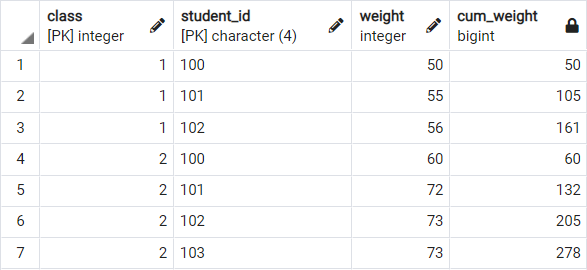
이렇게 하면 윈도우 함수를 사용했을 떄와 같은 결과를 얻을 수 있습니다.
만약 누적합의 순서를 바꾸고 싶다면 on절의 a.student_id <= b.student_id 와 같이 순서를 바꿔주면 됩니다.
누적합의 경우에도 윈도우 함수를 사용하는 것이 더 간단하고, 테이블을 1회만 스캔하기 때문에 테이블 스캔 관점에서는 윈도우함수의 사용이 조금 더 좋은 방법이라고 보여집니다.
1.3. 그룹 내 비율 구하기
다음으로 그룹 내에서 해당 행이 차지하는 비율이 어느정도인지 확인할 때를 생각해보겠습니다.
DBMS에 따라 ratio_to_report 함수를 제공하는 경우가 있지만 제가 사용해본 DBMS 에서는 제공하는 걸 본 적이 없어 다른 방식을 사용해보겠습니다.
목표
: class 별로 각 학생이 차지하는 몸무게의 비율을 구하기
< 윈도우 함수 이용 >
select class
, student_id
-- , weight
-- , sum(weight) over(partition by class) as tot_weight
, round(cast(weight as numeric)/cast(sum(weight) over(partition by class) as numeric)*100,2) as rto
from weights;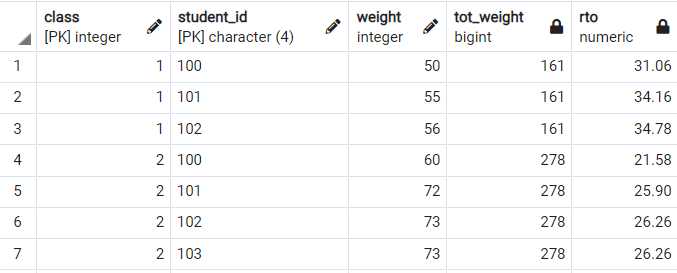
기본적인 원리는 윈도우 함수를 이용하여 class별 합을 구한 뒤 나누어주는 것입니다.
postgreSQL 에서는 숫자형이 정수형으로 되어있으면 나누었을 때 소수점을 표현하지 않는 문제가 있었습니다.
그래서 cast를 이용해서 숫자형을 numeric 으로 바꿔주었습니다. (decimal 로 바꿔줘도 됩니다.)
< 윈도우 함수를 사용하지 않을 경우 >
select a.class, a.student_id , weight , tot_weight
, round((cast(a.weight as numeric)/b.tot_weight)*100,2) as rto
from weights a
join (
select class, cast(sum(weight) as numeric) as tot_weight
from weights
group by 1
) b on a.class = b.class윈도우 함수를 이용하지 않을 경우에는 서브쿼리를 이용해서 class 별 몸무게의 합을 구해준 다음 join 을 통해 값을 결합해줍니다.
그런 후 값을 나누어주면 원하는 결과값을 확인할 수 있습니다.
이렇게 윈도우 함수를 이용하면 복잡한 쿼리를 간단하고 편리하게 작성할 수 있습니다.
그렇다면 윈도우 함수는 마법같이 좋은 점만 존재할까요?

2. 정말 윈도우 함수가 성능적으로 우수할까?
이렇게 윈도우 함수를 사용할 때와 그렇지 않을때를 비교해봤습니다.
윈도우 함수를 사용하면 무엇보다 아주 간단하게 쿼리를 작성할 수 있다는 장점이 있습니다.
그리고 테이블 스캔 횟수도 적으니 더 성능적으로 좋다고 생각이 들기도 합니다.
하지만 윈도우 함수는 행과 행간의 관계를 다루는 함수이기 때문에 윈도우 함수를 사용하면 기본적으로 정렬(Sort)의 과정이 생기게 됩니다.
정렬이 발생한다는 말은 SQL 의 성능이 저하된다는 의미입니다.
그렇기 때문에 테이블 스캔 횟수가 적다는 이유로 무조건 윈도우 함수를 사용하는게 좋아! 라는 결론은 잘못된 결론이 됩니다.
2.1. 윈도우 함수를 잘 사용하기 위해서는?
그렇다면 윈도우 함수를 잘 사용하기 위해서는 결국 불필요한 정렬을 줄여야 합니다.
기본적인 접근은 이전의 서브쿼리나 조인에 대한 게시글에서도 살펴봤듯, 스캔을 해야 할 행의 수를 줄이는 것입니다.
이를 위해서는 Join 이나 서브쿼리를 통해 레코드 수를 줄인 후 윈도우 함수를 사용하는 등의 방법을 고려해보는 것이 좋습니다.
해당 부분에 대한 내용도 이번 포스팅에서 살펴보고 싶지만, 아직까지 공부한 부분이 부족해 다음에 따로 포스팅을 해야할 것 같습니다.
우선 윈도우 함수가 성능적으로 좋지 않기 때문에 성능을 생각한다면 사용할 때 주의해야 된다는 점을 기억해두시면 좋겠습니다.
3. 정리하기
이렇게 이번 시간에는 윈도우함수에 대해서 알아봤습니다.
윈도우 함수의 소중함을 알아보려 시작한 내용이었는데 마음의 짐만 한가들 얻어가는 기분이네요...😿
그래도 힘내서 오늘 내용에서 생각을 해볼 부분을 정리하며 마치겠습니다.
1. 윈도우 함수는 복잡한 쿼리를 간단하게 작성할 수 있다는 아주 큰 장점이 있다.
& 테이블 스캔 횟수도 줄어든다는 장점도 있다.
2. 하지만 윈도우 함수를 사용하면 정렬(Sort)을 하게 되어 성능적으로 많은 실행 비용이 발생할 수 있다.
3. 그렇기 때문에 윈도우 함수를 사용할 땐 사전에 레코드의 수를 줄이는 것이 좋다.
4. 윈도우 함수를 사용할 때 고려할 부분은 따로 포스팅을 해서 소개드리겠습니다!
'#1 언어 노트 > #1.1. SQL 노트' 카테고리의 다른 글
| [SQL] MEDIAN 함수 없이 중앙값 구하기 (2) | 2022.07.24 |
|---|---|
| [SQL] SQL에서 정규표현식 활용하기 (3) | 2022.06.10 |
| [SQL] 성능 관점에서의 서브쿼리(Subquery) (13) | 2021.09.26 |
| [SQL] PIVOT/UNPIVOT 함수 없이 PIVOT/UNPIVOT 하기 (2) | 2021.08.18 |
| [SQL] 성능 관점에서 보는 결합(Join) (16) | 2021.08.13 |
블로그의 정보
고동의 데이터 분석
소라고동_