[SQL] 성능 관점에서 보는 결합(Join)
by 소라고동_0. 들어가며
결합(Join) 은 SQL 사용하게 되면 반드시 활용하는 기능입니다.
Inner Join, Outer Join 등 다양한 결합 방법이 존재하고 우리는 이를 활용해서 DB에 있는 여러 테이블을 활용할 수 있습니다.
하지만 저는 Join 의 기능을 활용해왔지만, 정작 join 연산이 어떻게 이루어지는지는 잘 모른채 사용하고 있었습니다.
그래서 이번 포스팅에서는 성능 관점에서 결합(Join)을 공부해볼텐데, 특히 Nested Loops Join 방식에 중점을 두고 공부를 진행해보겠습니다.
0.1 결합(Join)이란?
기본적인 결합의 종류는 다들 잘 아실거라 생각하여 아주 간단하게 이야기하고 넘어가겠습니다.
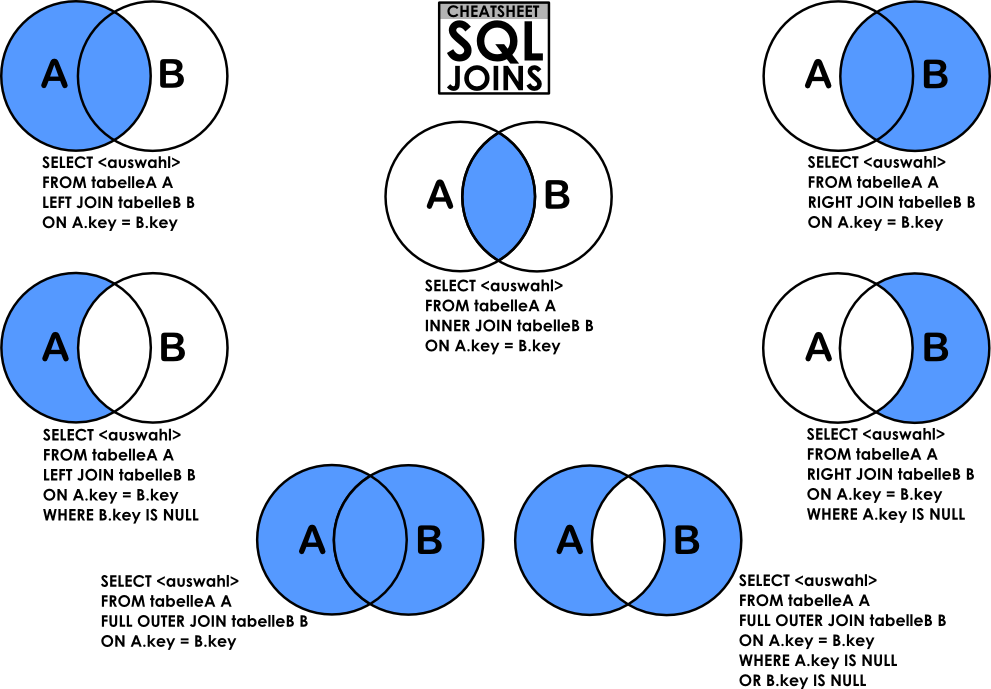
위 그림은 구글에서 'SQL join' 이라고 검색하면 아주 쉽게 찾을 수 있는 그림입니다.
내용을 살펴보면 Inner Join, Left/Right Outer Join 을 활용해서 테이블을 결합하고 원하는 부분만 추출할 수 있다는 것을 보여줍니다.
이렇듯 Join 의 목적은 둘 이상의 테이블을 결합하여 하나의 테이블처럼 사용하기 위함입니다.
그런데 업무를 하다보면 점점 많은 테이블을 조인하게 되고 쿼리가 돌아가는데 꽤 많은 시간이 걸린다는 것을 체감하게 됩니다.
물론 쿼리를 작성하면서 '이렇게 하면 좀 더 효율적이지 않을까?' 라는 생각으로 이런 저런 시도를 해보기도 합니다만... 조인이 내부에서 어떻게 이루어지는지 확실히 모르는 상태에서는 '정말 내 조치가 효율적인가?' 라는 질문에 대답을 할 수가 없었습니다.
그래서 이번 포스팅에서는 조인이 어떤 원리로 이루어지는지 알아보고 효율적인 조인의 방법에 대해 알아볼 예정입니다.
1. 결합(Join) 알고리즘과 성능
SQL에서 조인 연산을 수행할 때 내부적으로 선택되는 알고리즘의 종류는 아래와 같습니다.
1. Nested Loops Join
2. Hash Join
3. Sort Merge Join
물론 더 많은 조인 방식이 있지만 가장 대표적인 세가지 방식을 가져와봤습니다.
저 결함 알고리즘 중 어떤 알고리즘을 선택할지는 데이터의 크기, 결합키(Key), 인덱스(Index)와 같은 요인에 따라 옵티마이저가 결정하게 됩니다.
옵티마이저(Optimizer)
SQL 쿼리를 작성해서 실행을 시키면 그 쿼리는 옵티마이저(Optimizer)로 전송됩니다.
옵티마이저는 "최적화" 라는 의미인데, '데이터에 어떻게 접근하여 결과를 도출할지'가 최적화의 대상이 됩니다.
이때 데이터의 크기, 인덱스 유무 등의 여러 조건을 고려해서 선택 가능한 많은 '실행계획'을 작성하고,
각 선택지의 비용을 연산하고, 가장 낮은 비용을 가진 실행계획을 선택해줍니다.
즉, 여러 결과 도출 방법 중 가장 성능이 좋은 계획을 선택해주는 도구라고 정리할 수 있겠습니다.
이 중 Nested Loops Join 은 다른 결합 알고리즘의 기본이 되는 알고리즘이기 때문에 오늘은 Nested Loops Join 을 중점으로 살펴보도록 하겠습니다.
1.1. Nested Loops Join
Nested Loops Join은 이름 그대로 중첩 반복을 사용하는 알고리즘입니다.
그림으로 살펴보면 다음과 같습니다.

그림에 대해 조금 설명을 해보자면,
1. Table A와 Table B 가 어떤 Key 를 기준으로 결합을 진행합니다.
2. Table A (구동 테이블, Driving Table) 의 첫 번째 행에서 출발해 Table B (내부 테이블, Inner Table) 의 모든 행을 스캔합니다. 이때 결합 조건이 맞으면 값을 리턴합니다.
3. Table A 의 첫 번째 행의 스캔이 끝나면 두 번째 행이 Table B 의 모든 행을 스캔합니다.
4. 2~3번 과정을 반복하여 Table A 의 마지막 행이 Table B 의 모든 행을 스캔하면 결합이 완료됩니다.
설명을 읽어보면 우리가 흔히 사용하는 중첩 for 문의 원리와 같습니다.
Table A, Table B 의 결합 대상 레코드 수를 R(A), R(B) 라고 한다면 접근되는 레코드 수는 R(A) * R(B) 가 됩니다. (위 예시에서는 50개의 레코드에 접근하게 되겠네요)
조금 생각을 해보면 결국 Nested Loops Join 에서 실행시간은 R(A) * R(B) 에 비례하게되고, 성능을 높히기 위해선 R(A) * R(B) 의 값을 낮춰야한다는 것을 알 수 있습니다.
그럼 어떻게 성능을 높힐 수( = R(A)*R(B) 값을 낮출 수) 있을까요?
결론을 먼저 말하자면
"구동테이블(Driving Table)이 작을수록"
&
"내부 테이블(Inner Table)의 결합키 필드에 인덱스가 존재"
위 조건을 따르는 경우에 성능을 높힐 수 있습니다.
먼저 위 조건에서 등장하는 할 개념들에 대해서 간단히 살펴봅시다.
구동테이블(Driving Table)과 내부테이블(Inner Table)
구동테이블(Driving Table)이란 조인이 진행될 때 먼저 액세스 되어 Access Path 를 주도하는 테이블입니다
쉽게 이야기해보면 주도적으로 다른 테이블의 결합키에 다가가서 매칭을 시도하는 테이블 정도가 되겠습니다.
위 그림에서 예를 들어보면 Table A 의 행에서 출발해 Table B 의 각 행들을 스캔하기 시작합니다.
이 경우 Table A 가 구동테이블(Driving Table) 이 되고 Table B 는 내부테이블(Inner Table)이 됩니다.
인덱스(Index)
TABLE의 컬럼을 색인화(따로 파일로 저장)하여 테이블의 검색속도를 향상시키기 위한 자료구조입니다.
검색시 해당 TABLE의 레코드를 Full Scan 하는게 아니라 색인화 되어있는 INDEX 파일을 검색하여 검색속도를 빠르게 해줍니다.
그럼 다시 결론을 해석해봅시다.

내부 테이블의 결합키에 인덱스가 존재하게 되면 Driving Table 에서 Inner Table 로 스캔을 하러 갈 때 모든 행에 대해 스캔을 할 필요가 없게 됩니다.
즉, R(A) * R(B) 의 값이 줄어든다는 것이고, 이런 원리로 실행시간을 단축할 수 있습니다.
그런데 여기서 또 궁금한 점이 생겼습니다.
바로 '구동테이블이 어떻게 선택되는지?' 입니다. 그러니 이번엔 구동테이블 결정규칙에 대해 알아봅시다.
1.2. 구동테이블(Driving Table)은 어떻게 결정할까??
지금까지 내용의 결론은 '구동 테이블을 잘 선정해서 Join 을 해야겠다!' 라고 볼 수 있습니다.
하지만 아쉽게도(?) 구동테이블은 옵티마이저가 최적의 실행계획에 따라 결정을 하게 됩니다.
최적의 실행계획은 위의 "구동테이블이 작고 내부테이블 결합키에 인덱스가 존재하는 경우" 라는 조건에 따라 실행 비용을 최소화하는 방향으로 결정합니다. 만약 두 테이블 모두 인덱스가 있거나 없다면 레코드 수에 따라 옵티마이저가 알아서 구동테이블을 선택하게 됩니다.
그래서 우리는 옵티마이저를 믿고 join 연산을 수행하면 됩니다.
하지만 위 규칙과 무관하게 구동테이블이 정해지는 경우도 있습니다.
바로 Outer Join 을 실행할 경우인데요. 이유는 다음과 같습니다.
Inner Join 의 경우 어느 테이블을 먼저 읽어도 결과가 달라지지 않기 때문에 옵티마이저가 조인의 순서를 조절해 다양한 방법으로 최적화를 수행할 수 있습니다.
하지만 Outer Join 은 반드시 Outer 가 되는 테이블을 먼저 읽어야하기 때문에 옵티마이저가 조인의 순서를 선택할 수 없습니다.
즉, Left Outer Join 일 땐 왼쪽 테이블이, Right Outer Join 일 땐 오른쪽 테이블이 드라이빙 테이블이 됩니다.
구동 테이블을 선택하고자한다면 Inner Join 과 Outer Join 의 결과가 같을 경우 Outer Join 을 통해 구동테이블을 선택할 수 있겠습니다. 하지만 그냥 옵티마이저를 믿고 가는것도 좋은 방법이라고 생각합니다..ㅎ

그래도... 쿼리를 작성할 때 우리가 실행 계획을 제어(=구동테이블을 지정)할 수는 없을까요?
DBMS 마다 다르긴 하지만 "힌트(Hint)"라는 개념을 사용하면 사용자가 실행계획을 제어할 수 있습니다.
하지만 힌트를 사용하며 실행 계획을 제어할 경우 리스크를 짊어지게 됩니다.
데이터의 양과 카디널리티(Cardinality)는 DB를 운영하면서 계속 바뀌기 때문에 어떤 시점에 적절했던 실행계획이 또 다른 시점엔 부적절해질 수 있기 때문이죠. (옵티마이저의 경우 비용 기반 동적 실행계획을 세우기 때문에 이런 리스크를 어느정도 커버할 수 있습니다.)
그래서 힌트를 사용할 땐 이러한 위험을 검토하고 변화할 상황을 예측해서 적절한 실행계획을 세워야합니다.
이는 쉬운 작업은 아닌 것 같으므로 옵티마이저를 믿고 join 을 진행하는 것이 나아보입니다.
(SQL 작성 이후의 작업처리는 DBMS가 알아서 해주는 DBMS의 역할을 굳이 빼앗을 필요가 없는 것이죠.)
여기서 옵티마이저를 믿고 join을 하는것으로 이야기를 마무리하면 좋겠지만 이야기할 내용이 조금 더 남아있습니다..
실행계획을 옵티마이저에 맡겨도 최적의 실행계획이 선택되지 않는 경우가 있다는 것인데요.
대표적인 예시로는 장기적인 DB 운용중에 데이터양의 증가 등의 정보가 변해 실행계획이 안좋은 방향으로 변화하는 경우입니다.
사실 이렇게 유동적으로 변하는 환경에서 옵티마이저가 모든 경우에 대해 최적의 실행계획을 선택한다는 것은 말이 안되는 일일지도 모릅니다.
그리고 특히 Join 은 실행계획에 변동이 일어나기 가장 쉬운 연산입니다.
조인 시에는 여러가지의 알고리즘을 선택할 수 있고, 알고리즘이 변하면 성능이 변하기 때문이죠.
이런 상황에서 이상하게 들릴지도 모르지만 지금까지의 결론을 내린다면 이렇게 결론지을 수 있겠습니다.
SQL 쿼리에서 최대한 결합(Join)을 피하자.
밥먹듯 애용하는 조인인데 공부를 하고나니 결론이 조금 이상합니다.
결론의 의미는 "조인을 사용하지 말자" 라는게 아니라 "조인을 대체할 수 있는 다른 수단을 잘 활용하자!" 라는 느낌으로 받아들이시면 됩니다.
그 대체 수단은 앞으로 포스팅 할 예정입니다😊
(키워드만 미리 이야기해보면 바로 윈도우함수(Window Function) 입니다!)
2. 맺으며
이렇게 오늘은 Join에 대해 조금은 깊숙히 공부를 해봤습니다.
이번 포스팅을 통해 기억했으면 좋겠다는 부분은 정리를 해보면 이렇게 기록할 수 있겠습니다.
1. Join 방식 중 Nested Loops Join 의 원리와 성능 최적화의 조건
= "구동테이블이 작고, 내부테이블에 인덱스가 존재한다."
2. 구동테이블(Driving Table)과 내부테이블(Inner Table), 인덱스(Index)의 개념
3. 옵티마이저의 역할과 기능에 대한 믿음
= '아이 뭐 그런건 그냥 믿음으로 가는거지'
4. 효율적인 결합(Join)을 위해 공부해야하는 방향성
= 결합(Join)을 최소화할 수 있는 방법에 대해 공부하기
2.1. 공부를 하며 느낀점
사실 처음 이 부분을 공부하면서는
1. Join 의 원리 파악
2. 원리 이해로부터 성능 개선 방안 습득
3. 향후 쿼리 작성에 적용
4. 효율적이고 성능이 좋아진 내 쿼리!"
라는 결과를 기대했습니다.
하지만 공부를 하다보니 제가 조작할 수 있는 부분이 거의 없다는 것을 깨닫고 '아.. 의미가 없는 공부였나?' 라는 생각이 많이 들었습니다.
그래도 계속해서 자료를 찾아보고 생각을 정리하다보니 결국엔 의미있는 결론( = 조인을 최소화할 수 있는 방법 공부하기)을 낼 수 있었습니다.
뜻깊은 시간이었고 이후 포스팅에서는 결합을 최소화할 수 있는 방법에 대해 포스팅을 하도록 하겠습니다.
2.2 참고 자료
* 전체적인 내용
SQL 레벨업, 한빛미디어
* 구동테이블(Driving Table) 관련
https://jojoldu.tistory.com/173
https://devuna.tistory.com/36
* 인덱스(Index) 관련
https://velog.io/@gillog/SQL-Index%EC%9D%B8%EB%8D%B1%EC%8A%A4
* 옵티마이저(Optimizer) 관련
https://velog.io/@yewon-july/Optimizer
* 카디널리티(Cardinality) 관련
https://itholic.github.io/database-cardinality/
'#1 언어 노트 > #1.1. SQL 노트' 카테고리의 다른 글
| [SQL] MEDIAN 함수 없이 중앙값 구하기 (3) | 2022.07.24 |
|---|---|
| [SQL] SQL에서 정규표현식 활용하기 (5) | 2022.06.10 |
| [SQL] 윈도우 함수(Window Function)의 소중함을 느껴보자 (6) | 2021.12.19 |
| [SQL] 성능 관점에서의 서브쿼리(Subquery) (13) | 2021.09.26 |
| [SQL] PIVOT/UNPIVOT 함수 없이 PIVOT/UNPIVOT 하기 (3) | 2021.08.18 |
블로그의 정보
고동의 데이터 분석
소라고동_