[SQL] 성능 관점에서의 서브쿼리(Subquery)
by 소라고동_0. 들어가며
SQL 쿼리를 작성하다보면 서브쿼리를 자주 사용하게 됩니다.
서브쿼리는 '쿼리 안의 쿼리' 라고 생각을 하면 되는데, SQL 구문의 다양한 부분(SELECT, FROM, WHERE, HAVING, ORDER BY 절 등)에 사용할 수 있어 활용도가 높은 방식입니다.
각 위치에 따라 서브쿼리를 부르는 명칭이 달라지지만 이번 포스팅에서는 그런 부분보다 성능 관점에서의 서브쿼리, 서브쿼리를 잘 활용하는 방법에 대해 공부해보도록 하겠습니다.
(거창하게 시작하지만 조그마한 결론으로 마무리 되니 편하게 읽어주세요😊)
0.1. 서브쿼리(Subquery)란?
서브쿼리는 SQL 내부에서 작성되는 일시적인 테이블입니다.
여기서 '일시적인 테이블' 이라는 부분이 성능적인 차이를 불러옵니다.
SQL 구문 작성 시 활용하는 테이블(Table), 뷰(View), 서브쿼리(Subquery)에 대해서 설명을 해보면 아래와 같이 정리할 수 있습니다.
| 구분 | 설명 | 특징 |
| 테이블 (Table) | DB에 물리적으로 저장된 데이터 (영속적) | 영속적 |
| 뷰 (View) | 가상의 테이블, 접근할 때 마다 SELECT 구문이 실행됨 | 영속적, 물리적 저장 X |
| 서브쿼리 (Subquery) | 가상의 테이블, SQL 구문 실행 중에만 존재 | 일시적, 물리적 저장 X |
세가지 모두 데이터를 저장하고 있는 테이블로써 활용한다는 공통점이 있습니다.
하지만 각각의 성능 관점에서 차이점을 가져오는데요.
한번 예시를 보면서 이해를 해봅시다.
1) 테이블 (Table)
select * from receipts
DB에 저장되어 있는 테이블을 가져오기 때문에 빠르고 큰 비용없이 접근할 수 있다.
2) 뷰 (View)
create view vw_receipts
as
select *
from receipts
where cust_id = 'B';
select * from vw_receipts;
receipts 테이블에서 일부만을 가져와 vw_receipts 라는 하나의 가상 테이블(=뷰)를 만들었습니다.
장점 : 테이블 중 필요한 데이터만 가상 테이블로 저장하여 처리함으로써 관리가 편하고 SQL문이 간단해진다.
단점 : 독립적인 인덱스(Index)를 가질 수 없다. 접근할 때마다 SELECT 문에 구문이 실행되어 성능상의 문제를 유발시킬 수 있다.
즉, vw_receipts 라는 가상 테이블을 간편하게 사용할 수 있지만 이는 사실상 create view 를 할 때 작성한 select 문이 뒤에서 실행되는 것입니다.
따라서 테이블만큼의 빠른 접근은 어렵다는 점을 알아둘 필요가 있습니다.
3) 서브쿼리(Subquery)
select *
from (select * from receipts where cust_id = 'B') a;
receipts 테이블의 일부를 가져오기 위해 from 절에 서브쿼리를 사용했습니다.
SQL문의 from 절에서 서브쿼리가 하나의 뷰(View) 역할을 한다고 해서 인라인 뷰(Inline View)라는 이름을 붙혀주긴 하지만, 여기서는 그냥 서브쿼리를 활용했다는 정도로만 다루겠습니다.
장점 : SQL 구문 안에서 유연하게 또 다른 SQL문을 만들어 활용할 수 있다. 이로인해 코딩 시 편리함을 가져다준다.
단점 : 연산 비용이 추가된다, 최적화를 받을 수 없다, 쿼리가 복잡해진다.
이렇게 테이블, 뷰, 서브쿼리에 대해 살펴보았는데요.
이제는 오늘의 메인 주제인 서브쿼리의 장·단점에 대해서 자세히 살펴보도록 하겠습니다.
1. 서브쿼리의 특징
서브쿼리의 장점과 단점에 대해 알아보도록 하겠습니다.
1.1. 서브쿼리의 단점
결국 서브쿼리의 문제는 서브쿼리가 실체적인 데이터를 저장하고 있지 않다는 점에서 기인합니다.
위에서 언급한 서브쿼리의 단점 세 가지에 대해서 조금 더 자세히 살펴보겠습니다.
- 1) 연산 비용 추가
서브쿼리는 뷰(View)와 마찬가지로 서브쿼리는 가상의 테이블을 만드는 것입니다.
그렇기 때문에 서브쿼리에 접근할 때마다 SELECT 구문에 접근하여 데이터를 만들게 되고, 이로 인해 연산 비용이 늘어나게 됩니다.
서브쿼리가 간단할 경우엔 무리가 없지만 서브쿼리 안의 내용이 복잡해질수록 비용은 더욱 늘어납니다. - 2) 최적화를 받을 수 없다.
서브쿼리와 테이블이 가지는 큰 차이점은 서브쿼리엔 메타 정보가 담겨있지 않다는 점입니다.
즉, 명시적인 제약이나 인덱스가 작성되어있지 않다는 것입니다.
그렇기 때문에 옵티마이저가 쿼리에 접근하고 해석할 때 필요한 정보를 얻을 수 없게됩니다.
이는 내부적으로 복잡한 연산을 수행하거나 결과 크기가 큰 서브쿼리를 사용할 때 성능의 문제가 발생시키는 원인이 됩니다. - 3) 쿼리가 복잡해진다.
서브쿼리의 생김새를 다시한번 살펴보겠습니다.
위 예시에서는 from 절을 살펴볼 때 어느정도의 집중력이 필요합니다.select * from (select * from receipts where cust_id = 'B') a;
결국엔 SQL구문 하나를 해석해야되기 때문이죠.
지금은 간단한 서브쿼리가 사용되었지만 서브쿼리의 내용이 복잡해진다면 SQL구문 전체에 대한 가독성이 떨어지게 됩니다.
1.2. 서브쿼리의 장점
이러한 문제점을 가지고 있는 서브쿼리의 장점은 간단명료합니다.
쿼리 작성에 있어서 편리하다.
정말 달콤한 말입니다.
'편리하게 쓰면 되지 꼭 이것저것 고려해야해? 어차피 옵티마이저가 알아서 해주잖아. 그냥 믿고 가자'
라는 생각도 듭니다.
하지만 성능 관점에서 효율적인 쿼리를 작성하기 위해서 조금은 수고스럽지만 효율적인 방법을 생각해볼 필요가 있습니다!
비효율적인 서브쿼리의 모습을 살펴보면 달콤한 편리함에서 벗어날 의지가 생길지도 모르니 한번 예시를 살펴봅시다.
2. 서브쿼리를 활용한 예시
성능적 문제를 가져오는 서브쿼리와 이점을 가져오는 서브쿼리의 예시를 살펴보겠습니다.
2.1. 성능 문제를 가져오는 서브쿼리
예시에 사용할 Receipts 테이블의 생김새는 아래와 같습니다.
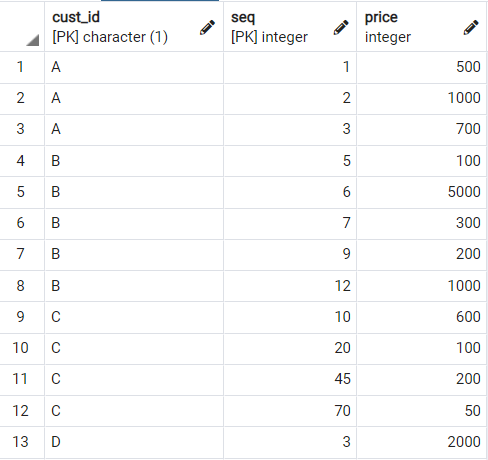
그럼 이 Receipts 테이블을 이용해서 서브쿼리를 활용한 예시를 살펴보겠습니다.
# Case 1.
Receipts 테이블에서 각 고객별 순번이 가장 빠른 row 를 가져오기 (= 가장 오래된 구입 내력 살펴보기)
* 서브쿼리를 이용하는 경우
select a.cust_id, seq, price
from receipts a
join (
select cust_id, min(seq) as min_seq
from receipts
group by 1
) b
on a.cust_id = b.cust_id
and a.seq = b.min_seq;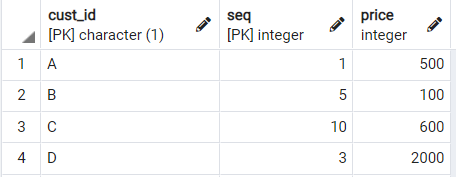
위 쿼리문의 장단점을 살펴보도록 합시다.
* 장점
쿼리를 작성하는 입장에서는 간.단.하.게. 서브쿼리로 조건에 맞는 필터링을 할 수 있다.
* 단점
1. 코드의 depth가 깊어지면서 코드가 복잡해져 코드를 읽는 입장에서는 가독성이 떨어진다.
2. 서브쿼리는 인덱스 또는 제약 정보를 가지지 않기 때문에 최적화되지 못한다.
= 서브쿼리로 추출된 가상 테이블과 Join 을 진행할 때 서브쿼리에 인덱스나 유일성 제약 등이 존재하지 않습니다.
이러한 점 때문에 결합 시 최적화가 이루어지지 않습니다.
(예시에선 테이블이 작아 문제가되지 않지만, 테이블이 아주 큰 경우엔 문제가 될 수 있습니다.)
3. 위 쿼리는 Join 연산을 수행하기 때문에 비용이 높고 실행 계획이 변동되는 리스크가 존재한다.
→ 이러한 점 때문에 지난 포스팅에서 '결합을 최대한 피하자' 라는 결론을 냈었습니다.
4. Receipts 테이블에 두 번 접근한다.
→ from 절에서 한 번, Join 안에 있는 서브쿼리에서 한 번.
간단한 쿼리문이었지만 생각보다 많은 단점이 존재합니다.
이 쿼리문의 문제의 핵심은 'Receipts 테이블에 두 번 접근하는 것'과 'Join 연산을 수행한다는 것'입니다.
그렇다면 성능이 좋으면서도 가독성 좋은 방법을 살펴봅시다.
* 윈도우 함수(Window Function)를 이용하는 경우
select cust_id, seq, price
from (
select cust_id, seq, price
, row_number() over(partition by cust_id order by seq asc) as rownum
from receipts
) a
where rownum = 1
이 쿼리는 이전의 쿼리의 문제점을 해결한 쿼리입니다.
이전 쿼리와의 비교.
단점1. 가독성이 떨어진다.
= Join 연산이 없어지고 select 절에서 from 절의 대부분의 정보를 획득할 수 있기 때문에 가독성이 좋아졌다.
단점2. 최적화되지 못한다.
= Join 연산이 사라져 메타 정보에 대한 영향이 상대적으로 적어졌다.
단점3. Join 연산으로 인한 문제점이 발생한다.
= Join 연산을 제거했다.
단점4. Receipts 테이블에 두 번 접근한다.
= Receipts 테이블에 한 번만 접근한다.
이렇게 윈도우함수를 활용함으로써 쿼리상의 문제를 간단하게 해결하였습니다.
⭐ 2.1.1. 서브쿼리 작성 시 고려할 점
하지만 여기서 드는 의문점이 있습니다.

윈도우 함수를 쓴 쿼리문에도 결국엔 서브쿼리를 이용했잖아.
그럼 이건 서브쿼리의 문제가 아니라 그냥 쿼리 작성의 문제인거 아닌가?
이 질문에 대해 크게 두 가지의 문제점을 생각해볼 수 있었습니다.
1. 불필요한 Join 연산을 수행했다는 점.
= 이 부분은 SQL 쿼리 작성에 있어서의 개선이 필요한 부분.
2. Join을 할 때 서브쿼리의 특징(= 가상 테이블, 실행 할 때 마다 select 문 실행) 때문에 특정 테이블의 접근이 불필요하게 많아졌다는 점.
= 서브쿼리를 활용할 때 테이블의 접근을 최소화 할 수 있는 방법을 고려해야 함.
이 내용을 정리해보면 이렇게 요약할 수 있습니다.
서브쿼리를 활용할 때 고려할 점
1. SQL 구문 전체에서 불필요한 Join 연산을 하지 않았는지?
2. 서브쿼리를 사용할 때 테이블 접근을 최소화 했는지?
그럼 이러한 점을 고려하여 SQL 구문을 작성한 예시를 하나만 더 살펴보겠습니다.
# Case 2.
각 고객별 구매 금액의 최대값 - 최소값을 구하기.
* 간편하게 작성한 SQL 구문
select a.cust_id
, (b.price - a.price) as diff
from (
-- 최소값 구하기
select a.cust_id, seq, price
from receipts a
join (
select cust_id, min(price) as min_price
from receipts
group by 1
) b
on a.cust_id = b.cust_id
and a.price = b.min_price
) a
join (
select a.cust_id, seq, price
from receipts a
join (
-- 최대값 구하기
select cust_id, max(price) as max_price
from receipts
group by 1
) b
on a.cust_id = b.cust_id
and a.price = b.max_price
) b
on a.cust_id = b.cust_id
order by cust_id
위 쿼리는 서브쿼리 활용 시 고려할 점을 생각하지 않은 쿼리입니다.
코드를 살펴보면 불필요한 Join 연산, 4번의 receipts 테이블 접근이라는 문제점을 가지고 있음을 확인할 수 있습니다.
이를 해결하기 위해서 쿼리를 다시 작성해보면.
select a.cust_id
, (max_price - min_price) as dif
from (
-- 최소값
select distinct cust_id
, min(price) over(partition by cust_id) as min_price
from receipts
) a
join (
-- 최대값
select cust_id
, max(max(price)) over(partition by cust_id) as max_price
from receipts
group by 1
) b
on a.cust_id = b.cust_id윈도우 함수를 이용하여 Join 연산의 횟수를 줄였고 Receipts 테이블의 접근을 2번으로 줄였습니다.
(윈도우 함수의 문법(?)에 대해서는 따로 포스팅을 할 예정이니 일단은 서브쿼리의 비효율을 줄였다는 것만 살펴봐주세요😊)
2.2 서브쿼리가 성능적으로 더 좋은 경우.
그렇다면 서브쿼리를 사용하는 것이 성능적으로 더 좋은 경우에 대해서 알아보도록 하겠습니다.
⭐ 2.2.1. Join 시 레코드 수 줄이기
아래의 두 테이블(Companies, Shops)을 이용해서 설명을 해보겠습니다.

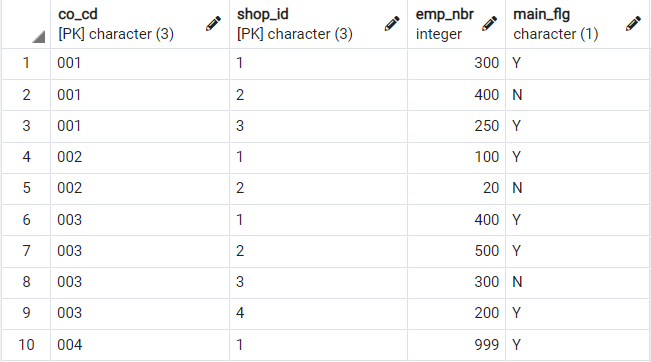
* 문제
두 테이블을 활용하여 main_flg = Y 인 사업소의 직원 수 구하기
( 레이아웃 : co_cd | district | emp_nbr )
방법1 : Join 을 먼저 수행한 후 필터링(집약, group by)
select a.co_cd, district, sum(emp_nbr) emp_nbr
from companies a
join shops b on a.co_cd = b.co_cd
where main_flg = 'Y'
group by 1,2
order by 1,2
방법 2 : 필터링(집약, group by)을 한 후 Join 수행
select a.co_cd, district, emp_nbr
from companies a
join (
select co_cd, sum(emp_nbr) emp_nbr
from shops
where main_flg = 'Y'
group by 1
) b
on a.co_cd = b.co_cd
order by 1,2위 두 방법은 같은 결과값을 보여주지만 성능적으로는 차이가 있습니다.
| 구분 | 레코드 수 |
| 방법 1 : Join 먼저 진행 | Companies 테이블 : 4개 Shops 테이블 : 10개 |
| 방법 2 : 필터링 먼저 진행 | Companies 테이블 : 4개 Shops 테이블 (서브쿼리) : 4개 |
서브쿼리를 이용해서 집약 및 필터링을 진행한 후 Join 연산을 수행하게 되면 Join 시 스캔하는 레코드의 수가 줄어드는 장점이 있습니다.
현재는 데이터가 작기 때문에 실행 속도에 큰 차이는 없겠지만 테이블이 커지고 데이터 양이 많아진다면 Join 레코드의 수를 줄이는 것이 효율적인 결과를 도출할 수 있습니다.
효율적인 서브쿼리 활용에 대해 간단히 정리하면 아래와 같이 정리할 수 있습니다.
Join 시 사전에 결합 레코드 수를 압축하여 Join 레코드의 수를 줄인다.
3. 맺으며
오늘은 SQL 에서 서브쿼리를 활용할 때 고려할 점에 대해 알아보았습니다.
결국은 서브쿼리 자체의 문제가 아닌 서브쿼리를 활용하는 방식의 문제라는 점으로 결론을 내려볼 수 있었습니다.
실제로 업무를 하면서 서브쿼리를 아무 생각없이 사용하는 경우가 많았는데, 앞으로는 주의하여 사용해봐야겠다는 생각을 하게되었습니다!
마지막으로는 이번 게시글을 정리하며 포스팅을 끝마치도록 하겠습니다.
3.1. 간단 요약
1. 서브쿼리는 SQL 구문 작성 시 다양하게 활용할 수 있는 편리한 도구이다.
2. 간편하고 유연하다는 장점이 있지만 성능적인 문제를 발생시킬 수 있다.
이는 서브쿼리가 '일시적인 테이블' 이라는 특성을 가지기 때문이다.
3. 성능적인 문제를 해결하기 위해 크게 두 가지를 고려해야한다.
= 불필요한 Join 연산을 수행하지 않는지.
= Join 시 불필요한 테이블 접근을 하지 않는지.
4. 위 두가지 고려사항과 함께 한 가지 방법을 활용하면 더욱 좋다.
= Join 시 서브쿼리를 활용하여 결합 레코드 수를 줄여 성능적 효율성을 높힌다.
'#1 언어 노트 > #1.1. SQL 노트' 카테고리의 다른 글
| [SQL] MEDIAN 함수 없이 중앙값 구하기 (2) | 2022.07.24 |
|---|---|
| [SQL] SQL에서 정규표현식 활용하기 (3) | 2022.06.10 |
| [SQL] 윈도우 함수(Window Function)의 소중함을 느껴보자 (6) | 2021.12.19 |
| [SQL] PIVOT/UNPIVOT 함수 없이 PIVOT/UNPIVOT 하기 (1) | 2021.08.18 |
| [SQL] 성능 관점에서 보는 결합(Join) (15) | 2021.08.13 |
블로그의 정보
고동의 데이터 분석
소라고동_